我的Bilibili主页:https://space.bilibili.com/10551374
5.15拼多多笔试
5.15 拼多多笔试
三个题目
1. Promise
有两个信号0和1。
- 先发送信号 1
- 200ms 后发送信号 0
- 100ms 后发送信号 1
- 150ms 后发送信号 0
- 在 300ms 重复以上过程 5 次
var delay = function(s) {
retrun new Promise(function(resolve, reject) {
setTimeout(resolve, s);
});
};
var n = 5;
while(n--){
delay().then(function(){
Signal(1);
return delay(200);
}).then(function(){
signal(0);
return delay(100);
}).then(function(){
signal(1);
return delay(150);
}).then(function(){
signal(0);
return delay(300);
})
}
2. 链表实现大整数加法
有两个链表 Listnode,头指针代表这个大整数的个位,往后是十位、百位,以此类推。用链表实现大整数加法。
// Listnode a, Listnode b 代表两个多位正整数;
var function plus(a, b){
var sum = new Listnode;
sum.head = a.head + b.head;
while (a.next || b.next) {
sum.next = a.next + b.next;
}
retrun sum;
}
3. Dom操作
<ul>
<li>item1</li>
<li>item2</li>
<li>item3</li>
<li>item4</li>
</ul>
有一个列表,默认背景为白色。
- 进入 ul 时,里面的 li 变为灰白相间的颜色;
- 进入 li 时,li 变成浅黄色;
- 离开 li 还在 ul 内部时,恢复到 1 的情况;
- 离开 ul 时变成全白。
使用鼠标事件
// 获取UL元素
var ul = document.getElementsByTagName('ul')[0];
// 获取所有LI元素
var liArr = ul.getElementsByTagName('li');
// 1. 当鼠标移入UL时,按Li的奇偶将背景颜色设置为灰色和白色
ul.onmouseover = function() {
for (var i = 0; i < liArr.length; i++) {
if (i % 2 === 0) {
liArr[i].style.backgroundColor = '#f2f2f2'; // 设置偶数项的背景色为 #f2f2f2
} else {
liArr[i].style.backgroundColor = '#fff'; // 设置奇数项的背景色为 #fff
}
}
};
// 2. 当鼠标移入特定Li时,对应的背景颜色设置为浅黄色
for (var i = 0; i < liArr.length; i++) {
liArr[i].onmouseover = function() {
this.style.backgroundColor = '#ffffe0'; // 设置当前LI元素的背景色为 #ffffe0
}
// 3. 如果鼠标移出了LI,但还在UL内部时,恢复1所描述的背景颜色;
liArr[i].onmouseout = function() {
ul.onmouseover();
}
}
// 4. 如果鼠标移出了UL则全部变回白色背景。
ul.onmouseout = function() {
for (var i = 0; i < liArr.length; i++) {
liArr[i].style.backgroundColor = '#fff'; // 设置所有LI元素的背景色为 #fff
}
};
5.9猫猫


5.10每日
1015. 可被 K 整除的最小整数
给定正整数 k ,你需要找出可以被 k 整除的、仅包含数字 **1** 的最 小 正整数 n 的长度。
返回 n 的长度。如果不存在这样的 n ,就返回-1。
注意: n 不符合 64 位带符号整数。
题解
class Solution {
public:
int smallestRepunitDivByK(int k) {
// 初始化变量n为1%k,即1对k取模的结果
int n = 1 % k;
// 循环k次,查找由若干个数字1组成的数能否被k整除
for (int i = 1; i <= k; ++i) {
// 如果n能够被k整除,说明我们找到了符合条件的数
if (n == 0) {
// 返回由若干个数字1组成的数的长度
return i;
}
// 如果n不能被k整除,继续迭代
n = (n * 10 + 1) % k;
}
// 如果循环k次仍然没有找到符合条件的数,返回-1
return -1;
}
};
5.7每日
1010. 总持续时间可被 60 整除的歌曲
在歌曲列表中,第 i 首歌曲的持续时间为 time[i] 秒。
返回其总持续时间(以秒为单位)可被 60 整除的歌曲对的数量。形式上,我们希望下标数字 i 和 j 满足 i < j 且有 (time[i] + time[j]) % 60 == 0。
示例 1:
输入:time = [30,20,150,100,40]
输出:3
解释:这三对的总持续时间可被 60 整除:
(time[0] = 30, time[2] = 150): 总持续时间 180
(time[1] = 20, time[3] = 100): 总持续时间 120
(time[1] = 20, time[4] = 40): 总持续时间 60
题解
hash。
class Solution {
public:
int numPairsDivisibleBy60(vector& time) {
vector rem(60); // 定义一个长度为 60 的数组 rem,用于记录元素余数出现的次数
int ans = 0; // 定义一个变量 ans,用于统计符合条件的配对个数
for (auto t : time) { // 遍历数组中的所有元素
int r = t % 60; // 计算元素 t 对 60 取模的余数
ans += rem[(60 - r) % 60]; // 先统计符合条件的配对数
rem[r]++; // 然后将余数为 r 的元素数量 +1,计入后续元素的配对统计中
}
return ans; // 返回符合条件的配对个数
}
};
5.4面试+携程笔试
显然是似了
笔试问题:
- vue3 和 vue2 有什么区别
- JSON.stringify() 的作用
- localStorage、session、cookie的区别
- 简述 Vuex 的核心概念和作用
- null 和 undefined 的区别
- 给定一个字符串,找出其中出现次数最多的字符。
- 写一个函数将树形结构数据转化为平铺结构
面试被拷打了,包括但不限于:
- 这个为什么要手写,这不就是一个很简单的组件吗
- 有还是没有
感觉甚至不敢问面试评价,显然很糟糕
需要多一些面试和项目经验,得写写demo
携程笔试
四个编程题
给一个字符串,如果是大写字母的话,变为它的下一个字母,如 A 变成 B,Z 变成 A;如果是小写字母的话,变为它的前一个字母,如 z 变成 y,a 变成 z,其他字符不变。(秒了)
第一行输入 n,表示数据组数。接下来每一行为 字符串 + 值 的形式,从中选择两个字符串,使得其中一个是另一个的字串,同时使得两个值的和最大。(strstr(a,b) 函数用于查找 b 在 a 第一次出现的位置,过了 95%)
有一个字符串由 0、1、2 构成,但是其中的某几位不可知,以 ?代替,但是满足以下条件:
- 相邻两个字符不相同;
- 任意连续三个字符组成的三进制数必定是偶数
思路:在三位三进制数中符合上述条件的只有:020(6)、101(10)、121(16)、202(20)
所以自然按位数分两种情况讨论:
- 一个是只有三位的情况,匹配上述四种情况的任意一种即可。
- 另一个是大于三位的情况,词此时字符串只能是020202……或202020……才能满足条件。
(过了 71%)
小明需要从编号为 1 的城市前往编号为 n 的城市,第一行输入 n,m,h,分别指代城市数、道路数、以及路程限制。
接下来 m 行,每行输入 u,v,w,d,指代从 u 和 v 之间的路径,道路承重、路程。
无法到达 n 输出 -1,在路程限制 h 的范围内,寻找车辆的最大承重。
输入:3 3 5 1 2 7 3 1 2 6 4 3 2 4 2输出: 6
解释:从 1 到 3 可以有两条路,1→3 或 1→2→3,路程分别为 4 和 5,承重最大为 6 和 4,需要输出可承重的最大值,即 6。
题解
#include#include #include #include using namespace std; const int INF = 1e9; const int MAXN = 100005; struct Edge { int to; // 目标节点编号 int w; // 边权值,即承重能力 int d; // 路径长度 Edge(int _to, int _w, int _d) : to(_to), w(_w), d(_d) {} }; vector graph[MAXN]; // 图的邻接表表示方式 int n, m, h; int dis[MAXN]; // dis[i]表示到节点i的最大承重能力 int weight[MAXN]; // weight[i]表示从起点到i节点经过的边权最大值 void dijkstra() { priority_queue
5.1每日
1376. 通知所有员工所需的时间
==Medium==
公司里有 n 名员工,每个员工的 ID 都是独一无二的,编号从 0 到 n - 1。公司的总负责人通过 headID 进行标识。
在 manager 数组中,每个员工都有一个直属负责人,其中 manager[i] 是第 i 名员工的直属负责人。对于总负责人,manager[headID] = -1。题目保证从属关系可以用树结构显示。
公司总负责人想要向公司所有员工通告一条紧急消息。他将会首先通知他的直属下属们,然后由这些下属通知他们的下属,直到所有的员工都得知这条紧急消息。
第 i 名员工需要 informTime[i] 分钟来通知它的所有直属下属(也就是说在 informTime[i] 分钟后,他的所有直属下属都可以开始传播这一消息)。
返回通知所有员工这一紧急消息所需要的 分钟数 。
示例 1:
输入:n = 1, headID = 0, manager = [-1], informTime = [0]
输出:0
解释:公司总负责人是该公司的唯一一名员工。
示例 2:
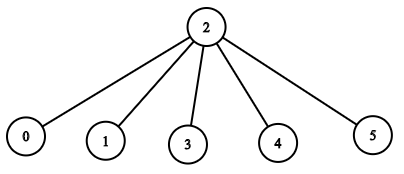
输入:n = 6, headID = 2, manager = [2,2,-1,2,2,2], informTime = [0,0,1,0,0,0]
输出:1
解释:id = 2 的员工是公司的总负责人,也是其他所有员工的直属负责人,他需要 1 分钟来通知所有员工。
上图显示了公司员工的树结构。
题解
class Solution {
public:
int numOfMinutes(int n, int headID, vector& manager, vector& informTime) {
// 创建一个存储有向图的邻接表 g,节点个数为 n
vector> g(n);
// 根据 manager 数组,将每个员工连接到其直接上级员工的节点上
for (int i = 0; i < n; ++i) {
if (manager[i] >= 0) {
g[manager[i]].push_back(i);
}
}
// 创建一个 lambda 函数 dfs,用于对不同节点进行深度优先遍历,以计算从 headID 节点开始,每个员工被通知所需的最短时间
function dfs = [&](int i) -> int {
int ans = 0; // 定义 ans 变量,表示通知 i 节点需要的时间
// 遍历节点 i 的所有下属节点 j
for (int j : g[i]) {
// 对 j 节点进行深度优先遍历,找到 j 节点及其下属节点被通知所需的最长时间
ans = max(ans, dfs(j) + informTime[i]); // 这里的 + informTime[i] 表示从 i 节点到 j 节点通知所需的时间
}
return ans; // 返回通知 i 节点需要的最短时间
};
// 对 headID 节点进行深度优先遍历,计算从 headID 节点开始,所有员工被通知所需的最短时间中的最大值
return dfs(headID);
}
};
4.30每日
1033. 移动石子直到连续
三枚石子放置在数轴上,位置分别为 a,b,c。
每一回合,你可以从两端之一拿起一枚石子(位置最大或最小),并将其放入两端之间的任一空闲位置。形式上,假设这三枚石子当前分别位于位置 x, y, z 且 x < y < z。那么就可以从位置 x 或者是位置 z 拿起一枚石子,并将该石子移动到某一整数位置 k 处,其中 x < k < z 且 k != y。
当你无法进行任何移动时,即,这些石子的位置连续时,游戏结束。
要使游戏结束,你可以执行的最小和最大移动次数分别是多少? 以长度为 2 的数组形式返回答案:answer = [minimum_moves, maximum_moves]
示例 1:
输入:a = 1, b = 2, c = 5
输出:[1, 2]
解释:将石子从 5 移动到 4 再移动到 3,或者我们可以直接将石子移动到 3。
题解
我们先将 a,b,c 排序,记为 x,y,z, 即 x<y<z。
接下来分情况讨论:
如果 z−x≤2,说明 3 个数已经相邻,不用移动,结果为 [0,0];
否则,如果 y−x<3,或者 z−y<3,说明有两个数只间隔一个位置,我们只需要把另一个数移动到这两个数的中间,最小移动次数为 1;其他情况,最小移动次数为 2;
最大移动次数就是两边的数字逐个往中间靠,最多移动 z−x−2 次。
最后将最小移动次数、最大移动次数返回即可。
class Solution {
public:
vector numMovesStones(int a, int b, int c) {
int x = min({a, b, c});
int z = max({a, b, c});
int y = a + b + c - x - z;
int mi = 0, mx = 0;
if (z - x > 2) {
mi = y - x < 3 || z - y < 3 ? 1 : 2;
mx = z - x - 2;
}
return {mi, mx};
}
};
4-29每日
2423. 删除字符使频率相同
==Easy==
给你一个下标从 0 开始的字符串 word ,字符串只包含小写英文字母。你需要选择 一个 下标并 删除 下标处的字符,使得 word 中剩余每个字母出现 频率 相同。
如果删除一个字母后,word 中剩余所有字母的出现频率都相同,那么返回 true ,否则返回 false 。
注意:
- 字母
x的 频率 是这个字母在字符串中出现的次数。 - 你 必须 恰好删除一个字母,不能一个字母都不删除。
示例 1:
输入:word = "abcc"
输出:true
解释:选择下标 3 并删除该字母,word 变成 "abc" 且每个字母出现频率都为 1 。
题解
我们先用哈希表或者一个长度为 26 的数组 freq 统计字符串中每个字母出现的次数。
接下来,枚举 26 个字母,如果字母 s 在字符串中出现过,我们将其出现次数减一,然后判断剩余的字母出现次数是否相同。如果相同,返回 true,否则将 s 的出现次数加一,继续枚举下一个字母。
枚举结束,说明无法通过删除一个字母使得剩余字母出现次数相同,返回 false。
class Solution {
public:
// 类成员变量 freq 数组,用于存储字符的出现次数
int freq[26];
bool equalFrequency(string word) {
// 第一次遍历字符串,统计字符出现的次数
for (char s : word) {
++freq[s - 'a'];
}
// 第二次遍历 freq 数组,依次将每个字符的出现次数减 1,判断剩余字符的频数是否相同
for (int i = 0; i < 26; ++i) {
if (freq[i] != 0) {
freq[i]--; // 将当前字符的出现次数减 1
bool flag = true; // 标记剩余字符是否频数相同的标志
int x = 0; // 中间变量,用于存储某个字符的频数
for(int j = 0; j < 26; ++j) {
if (freq[j] == 0) { // 如果这个字符的出现次数已经是 0,那么跳过它
continue;
}
else if (x == 0 && freq[j] != 0) { // 如果 x 是 0,并且这个字符的出现次数不是 0,那么将 x 赋值为这个字符的出现次数
x = freq[j];
}
else { // 如果 x 不是 0,并且这个字符的出现次数也不是 0
if (x == freq[j]) { // 如果 x 等于这个字符的出现次数,那么说明剩余字符的频数仍然相同
continue;
}
else { // 否则说明剩余字符的频数不相同
flag = false;
}
}
}
if (flag) { // 如果剩余字符的频数相同,那么说明存在一种方法,使得剩余字符的每个字符出现次数相等
return true;
}
else { // 否则说明剩余字符的频数不相同,恢复 freq 数组,并检查下一个字符
freq[i]++;
continue;
}
}
}
return false; // 如果遍历完 freq 数组都没有找到符合要求的字符,那么返回 false
}
};
4-28每日
1172. 餐盘栈
==Hard==
我们把无限数量 ∞ 的栈排成一行,按从左到右的次序从 0 开始编号。每个栈的的最大容量 capacity 都相同。
实现一个叫「餐盘」的类 DinnerPlates:
DinnerPlates(int capacity)- 给出栈的最大容量capacity。void push(int val)- 将给出的正整数val推入 从左往右第一个 没有满的栈。int pop()- 返回 从右往左第一个 非空栈顶部的值,并将其从栈中删除;如果所有的栈都是空的,请返回-1。int popAtStack(int index)- 返回编号index的栈顶部的值,并将其从栈中删除;如果编号index的栈是空的,请返回-1。
示例:
输入:
["DinnerPlates","push","push","push","push","push","popAtStack","push","push","popAtStack","popAtStack","pop","pop","pop","pop","pop"]
[[2],[1],[2],[3],[4],[5],[0],[20],[21],[0],[2],[],[],[],[],[]]
输出:
[null,null,null,null,null,null,2,null,null,20,21,5,4,3,1,-1]
解释:
DinnerPlates D = DinnerPlates(2); // 初始化,栈最大容量 capacity = 2
D.push(1);
D.push(2);
D.push(3);
D.push(4);
D.push(5); // 栈的现状为: 2 4
1 3 5
﹈ ﹈ ﹈
D.popAtStack(0); // 返回 2。栈的现状为: 4
1 3 5
﹈ ﹈ ﹈
D.push(20); // 栈的现状为: 20 4
1 3 5
﹈ ﹈ ﹈
D.push(21); // 栈的现状为: 20 4 21
1 3 5
﹈ ﹈ ﹈
D.popAtStack(0); // 返回 20。栈的现状为: 4 21
1 3 5
﹈ ﹈ ﹈
D.popAtStack(2); // 返回 21。栈的现状为: 4
1 3 5
﹈ ﹈ ﹈
D.pop() // 返回 5。栈的现状为: 4
1 3
﹈ ﹈
D.pop() // 返回 4。栈的现状为: 1 3
﹈ ﹈
D.pop() // 返回 3。栈的现状为: 1
﹈
D.pop() // 返回 1。现在没有栈。
D.pop() // 返回 -1。仍然没有栈。
题解
方法一:栈数组 + 有序集合
我们定义以下数据结构或变量:
capacity:每个栈的容量;stacks:栈数组,用于存储所有的栈,其中每个栈的最大容量都是capacity;not_full:有序集合,用于存储所有未满的栈在栈数组中的下标。
对于 push(val) 操作:
- 我们首先判断
not_full是否为空,如果为空,则说明没有未满的栈,需要新建一个栈,然后将val压入该栈中,此时判断容量capacity是否大于 1,如果大于 1,则将该栈的下标加入not_full中。 - 如果
not_full不为空,则说明有未满的栈,我们取出not_full中最小的下标index,将val压入stacks[index]中,此时如果stacks[index]的容量等于capacity,则将index从not_full中删除。
对于 popAtStack(index) 操作:
- 我们首先判断
index是否在stacks的下标范围内,如果不在,则直接返回 −1。如果stacks[index]为空,同样直接返回 −1。 - 如果
stacks[index]不为空,则弹出stacks[index]的栈顶元素val。如果index等于stacks的长度减 1,则说明stacks[index]是最后一个栈,如果为空,我们循环将最后一个栈的下标从not_full中移出,并且在栈数组stacks中移除最后一个栈,直到最后一个栈不为空、或者栈数组stacks为空为止。否则,如果stacks[index]不是最后一个栈,我们将index加入not_full中。 - 最后返回
val。
对于 pop() 操作:
- 我们直接调用
popAtStack(stacks.length - 1)即可。
class DinnerPlates {
public:
DinnerPlates(int capacity) {
this->capacity = capacity;
}
// 插入元素,push 方法会将元素插入到最早有空闲栈的末尾或者新建一个栈
void push(int val) {
// 如果不存在有空闲栈,就新建一个栈,并把元素压入
if (notFull.empty()) {
stacks.emplace_back(stack());
stacks.back().push(val);
// 如果栈的容量大于 1,那么表示该栈还有余地,需要将其纳入有空闲栈的集合
if (capacity > 1) {
notFull.insert(stacks.size() - 1);
}
} else {
// 否则,找到有空闲栈中的最小索引,将元素压入到该栈的末尾
// 注意,这里的索引是集合中最小的索引,而不是数组下标
int index = *notFull.begin();
stacks[index].push(val);
if (stacks[index].size() == capacity) {
// 如果当前栈已经达到容量上限,就将其从集合中移除
notFull.erase(index);
}
}
}
// 弹出最后一个栈的栈顶元素,如果没有任何元素就返回 -1
int pop() {
return popAtStack(stacks.size() - 1);
}
// 弹出指定栈的栈顶元素,如果栈为空或者索引越界就返回 -1
int popAtStack(int index) {
if (index < 0 || index >= stacks.size() || stacks[index].empty()) {
// 如果索引越界或者栈为空,就返回 -1
return -1;
}
// 否则,弹出该栈的栈顶元素,并检查该栈是否已经空了
int val = stacks[index].top();
stacks[index].pop();
if (index == stacks.size() - 1 && stacks[index].empty()) {
// 如果当前弹出的是最后一个栈的元素,并且该栈已经空了,
// 就需要将数组末尾也为空的栈移除掉,同时更新有空闲栈的集合
while (!stacks.empty() && stacks.back().empty()) {
notFull.erase(stacks.size() - 1);
stacks.pop_back();
}
} else {
// 如果弹出的是中间的某个栈的元素,就将其索引加入到有空闲栈的集合之中
notFull.insert(index);
}
return val;
}
private:
int capacity; // 定义栈的容量
vector> stacks; // 维护多个栈
set notFull; // 存储有空闲栈的索引
};
/**
* Your DinnerPlates object will be instantiated and called as such:
* DinnerPlates* obj = new DinnerPlates(capacity);
* obj->push(val);
* int param_2 = obj->pop();
* int param_3 = obj->popAtStack(index);
*/
4-27每日
1048. 最长字符串链
给出一个单词数组 words ,其中每个单词都由小写英文字母组成。
如果我们可以 不改变其他字符的顺序 ,在 wordA 的任何地方添加 恰好一个 字母使其变成 wordB ,那么我们认为 wordA 是 wordB 的 前身 。
- 例如,
"abc"是"abac"的 前身 ,而"cba"不是"bcad"的 前身
词链是单词 [word_1, word_2, ..., word_k] 组成的序列,k >= 1,其中 word1 是 word2 的前身,word2 是 word3 的前身,依此类推。一个单词通常是 k == 1 的 单词链 。
从给定单词列表 words 中选择单词组成词链,返回 词链的 最长可能长度 。
示例 1:
输入:words = ["a","b","ba","bca","bda","bdca"]
输出:4
解释:最长单词链之一为 ["a","ba","bda","bdca"]
题解
排序 + 哈希表
根据题目描述,字符串链中的单词必须按照长度递增的顺序排列。因此,我们首先对数组 words 中的字符串按照长度进行升序排序。在排好序的数组中,如果字符串 a 是字符串 b 的前身,那么字符串 a 的长度一定是字符串 b 的长度减去 1。
我们可以使用哈希表 d 存储排好序的数组中的每个字符串的最长字符串链长度。
接下来,遍历数组 words 中的每个字符串 s,计算出它的所有前身字符串 t,每一个前身字符串 t 是将字符串 s 中的一个字符删除后得到的。如果哈希表中存在字符串 t,那么我们就能够用 d[t]+1 更新 d[s],即 d[s]=max(d[s],d[t]+1)。然后我们更新答案为所有 d[s] 中的最大值。
遍历结束后,返回答案即可。
代码
class Solution {
public:
int longestStrChain(vector& words) {
// 将单词按照长度递增排序
sort(words.begin(), words.end(), [](auto &a, auto &b) { return a.size() < b.size(); });
int ans = 0;
unordered_map d; // 哈希表 d 存储以某个单词为链尾的最长链长度
for (auto &s : words) {
int x = 1; // 将自己看作一个长度为 1 的链
for (int i = 0; i < s.size(); ++i) {
// 枚举 s 中每个位置,假设删掉该位置上的字符后的字符串为 t
string t = s.substr(0, i) + s.substr(i + 1);
x = max(x, d[t] + 1); // 更新以 s 为链尾的最长链长度
}
d[s] = x; // 更新哈希表
ans = max(ans, x);
}
return ans; // 返回最长链长度
}
};
4-26每日
1031. 两个非重叠子数组的最大和
给你一个整数数组 nums 和两个整数 firstLen 和 secondLen,请你找出并返回两个非重叠 子数组 中元素的最大和,长度分别为 firstLen 和 secondLen 。
长度为 firstLen 的子数组可以出现在长为 secondLen 的子数组之前或之后,但二者必须是不重叠的。
子数组是数组的一个 连续 部分。
示例 1:
输入:nums = [0,6,5,2,2,5,1,9,4], firstLen = 1, secondLen = 2
输出:20
解释:子数组的一种选择中,[9] 长度为 1,[6,5] 长度为 2。
题解

代码
class Solution {
public:
int maxSumTwoNoOverlap(vector &nums, int firstLen, int secondLen) {
int ans = 0, n = nums.size(), s[n + 1]; // 定义变量
s[0] = 0;
partial_sum(nums.begin(), nums.end(), s + 1); // partial_sum 函数计算 nums 的前缀和
// 定义一个 lambda 函数对象,用于计算两个相离的子数组的最大和
auto f = [&](int firstLen, int secondLen) {
int maxSumA = 0;
for (int i = firstLen + secondLen; i <= n; ++i) { // 遍历 s 数组,计算 A、B 两个子数组的最大和
// 计算 A 子数组的最大和
maxSumA = max(maxSumA, s[i - secondLen] - s[i - secondLen - firstLen]);
// 计算 A、B 两个子数组的总和,并更新最大值
ans = max(ans, maxSumA + s[i] - s[i - secondLen]);
}
};
// 分别计算左 a 右 b 和左 b 右 a 两个方案的最大和,并取两个方案的最大值
f(firstLen, secondLen); // 左 a 右 b
f(secondLen, firstLen); // 左 b 右 a
return ans; // 返回最大和
}
};